2021년 4월부터 6월 말 까지 진행한 Naver Ai Rush 후기입니다.
대회 소개

네이버에서 주최하는 모델링 대회입니다.
진행
- 총 2라운드로 진행
- 각 라운드마다 과제를 개개인이 선택하여 진행
특징
실제 데이터 활용
- 실제 네이버 서비스에서 생산된 데이터를 학습 데이터로 활용합니다.
- 실제 서비스 데이터를 대규모로 학습에 활용할 기회는 학부생에게 흔치 않은 기회라 이 대회에 관심을 가지게 된 가장 큰 이유였습니다.
우승자 특전
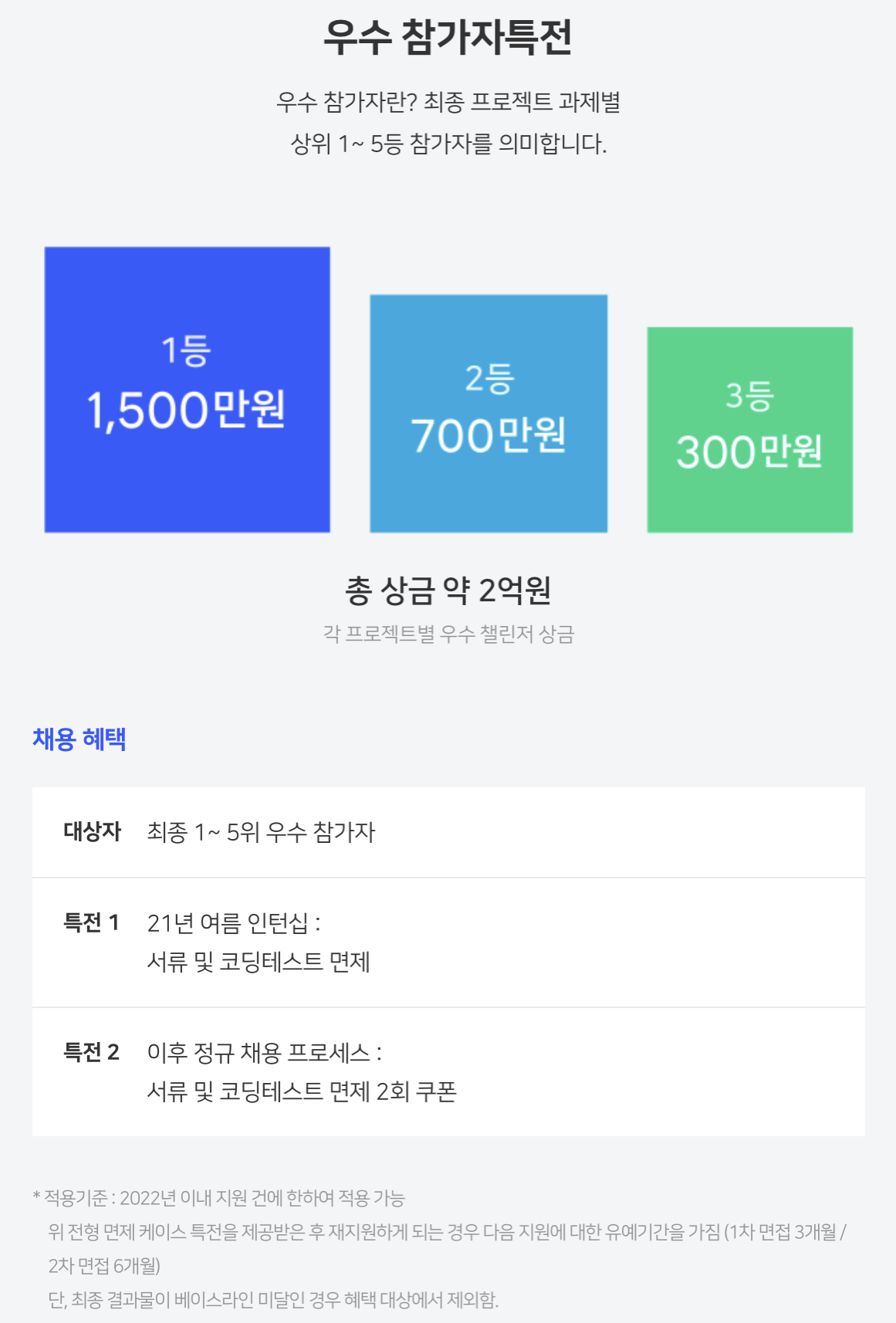
- 각 과제에 최종 1~3등까지는 많은 상금이 지급됩니다.
- 각 과제에 최종 1~5위에게 서류 및 코딩테스트 면제 2회 쿠폰이 주어집니다.
- 이 특전 역시 대회에 관심을 가지게 된 이유중 하나였습니다.
일정
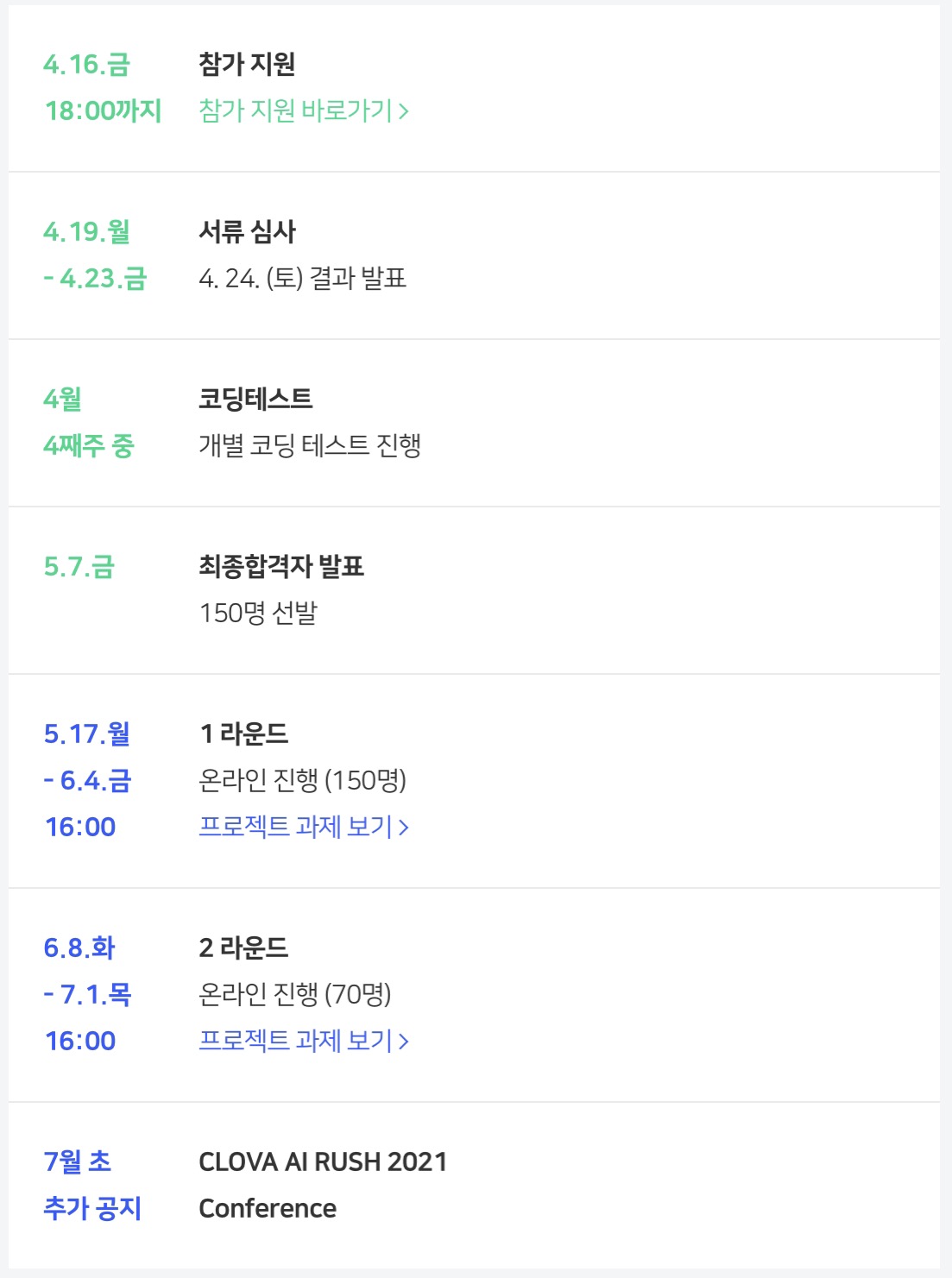
대회 일정별로 후기를 더 자세하게 적어보겠습니다.
참가 지원
지원 계기
대학에 입학했지만 코시국이라 집에서만 시간을 보내는 친구들과 같이 참여할 공모전을 찾던 중에 네이버 AI Rush라는 대회가 눈에 들어왔습니다.
위에서 언급한 여러 특징들 때문에 관심이 생겼고, 지원 자격에 머신러닝/딥러닝 모델링 개발에 관심이 있거나 경험이 있는 누구나 CLOVA AI RUSH 2021 전체 진행 기간 참여가 가능한 분 이라고 되어있어서 지원을 결심하게 됩니다.
지원 과정
지원신청 페이지에 가보니 몇가지 질문과 깃허브 링크를 제출해야해서 작성하고 제출했습니다.
제출하고 난 뒤 대회 주최사가 Naver다 보니 저는 당연히 서류 탈락일줄 알고 기대도 안하고 있었습니다. 그런데 서류 합격 메일이 날아와서 좀 놀랐습니다.
너무 성의없게만 적지 않으면 보통 서류는 통과하는것 같습니다.
코딩테스트
코딩테스트가 서류 합격 통보를 받고 일주일 뒤에 진행되어서 일주일동안 급하게 백준좀 었습니다.
막상 코딩테스트를 풀어보니 그렇게 난이도가 어렵지 않았습니다. 구현한 알고리즘이 정확이 맞았는지는 알려주지 않았지만, 시간이 엄청 부족하거나 그러지는 않았습니다.
백준 티어로 생각해보면 대략 실버2~골드5 정도 되었던거 같습니다.
코딩테스트는 생각보다 무난히 합격하게 됩니다.
대회 진행
1라운드
이제 본격적으로 대회에 참가하게 됩니다.
1라운드는 선택 가능한 과제가 총 5가지가 있었습니다.
- 회원&인증 플랫폼 - 회원 키보드, 마우스 기록을 통한 어뷰징 탐지
- 지도 개발 - 실시간 버스 도착 예정시간 예측 정확도 향상
- 포토클라우드 개발 - 네이버 클라우드 MYBOX에 들어가는 이미지 분류 테마의 확대 적용
- 쇼핑 AI 개발 - 쇼핑 카테고리 분류
- CLOVA ML X - 스마트스토어 SKU단위 수요 예측
그중 저는 2번 과제를 선택했습니다.
과제 설명
2번 과제는 서울 버스중 지정된 한 노선의 도착 예정 시간을 예측하는 과제였습니다.
제공된 데이터는 버스 위치, 정류장 등 버스 정보를 기록한 로그와 다음 정류장까지 이동하는데 걸리는 시간이었습니다.
모델은 RMSE로 평가하였습니다.
분석 및 학습
1차 시도
처음에는 월/요일/시간에 따라 정류장 이동 시간에 일정한 패턴이 있을거라고 생각했습니다. 출퇴근 시간, 명절, 비/눈이오는 날씨 등 여러 요인에 따라 교통상황이 바뀌고, 버스 역시 그 영향을 받을것 이라고 생각했기 때문입니다.
그래서 처음에는 1D CNN 레이어를 이용하여 모델을 학습했습니다. 하지만 일정 수준 이상으로 오차율이 줄지 않았고, 데이터를 다시한번 분석해 보았습니다.
2차 시도
이번에는 데이터가 시간순으로 기록되었다는 점에서 RNN 레이어를 사용해보기로 결정했습니다. 데이터 특성상 이전 정류장 도착 기록이 그다음 정류장 도착 기록에도 영향이 있을것 같았기 때문입니다.
실제로도 오차율이 많이 줄었고, 1라운드는 6등으로 마무리 하며 2라운드에 진출할 수 있었습니다.
2라운드
2라운드는 선택 가능한 과제가 총 8가지가 있었습니다.
- TUNE - 재생 및 메타데이터를 활용한 음악 추천
- 지도 개발 - 네비게이션 사용자 주행 기록을 이용한 통행 코드 오류 탐지
- AiRS - 네이버 모바일 메인 마이구독의 UGC 콘텐츠 추천을 위한 문서 키워드 추출
- 스마트 에디터 - 스마트에디터 문법 교정 도우미(Grammar Correction Assistant) 기능 고도화
- 쇼핑 AI 개발 - 쇼핑 카탈로그 클러스터링
- G플레이스 AI 개발 - 글로벌 메뉴명 분석
- Biz CIC AI 개발 - 디스플레이 광고 클릭 예측
- CLOVA ML X - 대규모 쇼핑 데이터를 활용한 일반적인 유저 임베딩 추출
이번에도 2번 과제를 선택했습니다.
과제 설명
2번 과제는 실제 네이버 지도 사용자들의 주행 데이터를 이용하여 실제로는 갈 수 없는 지점이 갈 수 있다고 표기되어있는 오류를 탐지하는 주제였습니다.
오류인 데이터는 0, 오류가 아닌 데이터는 1로 표기되어있는 이진분류 문제였고, 모델 평가 방식은 F1-Score를 이용하였습니다.
분석 및 학습
1차 시도
처음에는 수치형 데이터와 원핫인코딩한 범주형 데이터를 하나로 묶어서 학습시켰습니다.
하지만 스코어가 0이 나오며 전혀 학습이 되지 않았습니다.
2차 시도
데이터를 조금 더 분석해보니 class가 대부분 오류 없음을 나타내는 0에 치우쳐저 있다는 특징을 발견하게 됩니다.
그래서 불균형 데이터를 학습하는 방법에 대해 찾아보았고, imblearn이라는 라이브러리를 찾게 되었습니다. imblear은 데이터를 오버/언더 샘플링 하여 라벨 개수를 맞춰주는 라이브러리입니다.
언더샘플링을 하면 데이터의 대부분을 활용할 수 없게되기 저는 오버샘플링을 통해 데이터의 균형을 맞췄습니다. 그 결과, 학습이 어느정도 진행되어 스코어가 나오게 되었습니다.
3차 시도
이번에는 범주형 데이터와 수치형 데이터를 따로 넣어주어 학습을 시킨 후, 하나로 합치는 방법으로 학습을 시켜보았습니다.
케라스로 멀티인풋 모델을 구성하여 학습한 결과, 2라운드는 최종적으로 8위로 마무리하게 됩니다.
소감
아쉬운점
- 많은 프로젝트를 시도해보지 못했습니다.
대부분의 베이스라인코드가 파이토치로 작성되어있어서 시도조차 해보지 못했습니다. 다양한 형식의 데이터를 학습해볼 기회였는데, 시도도 못해봐서 많이 아쉽습니다. - 대회 기간이 조금 아쉬웠습니다.
대회 진행 기간이 대학교 시험기간과 겹쳐서 대회에 온전히 집중하지 못했습니다. 막판에 조금만 더 집중했다면 순위가 달라졌을까 하는 아쉬움이 남습니다.
좋았던점
- 다양한 시도를 해볼 수 있었습니다.
제가 처음 접해보는 유형의 데이터가 많아서 다양한 시도를 해봤습니다. 지금까지는 잘 정제된 데이터만 다루어 봤는데, 여기서는 서비스 데이터들을 이용해서 좋은 기회였던거 같습니다. - 많은 새로운 것들을 배웠습니다.
데이터를 분석하는 방법, 데이터를 학습시키는 방법, 코드를 작성하는 방법 등 많은 부분에서 배웠습니다.